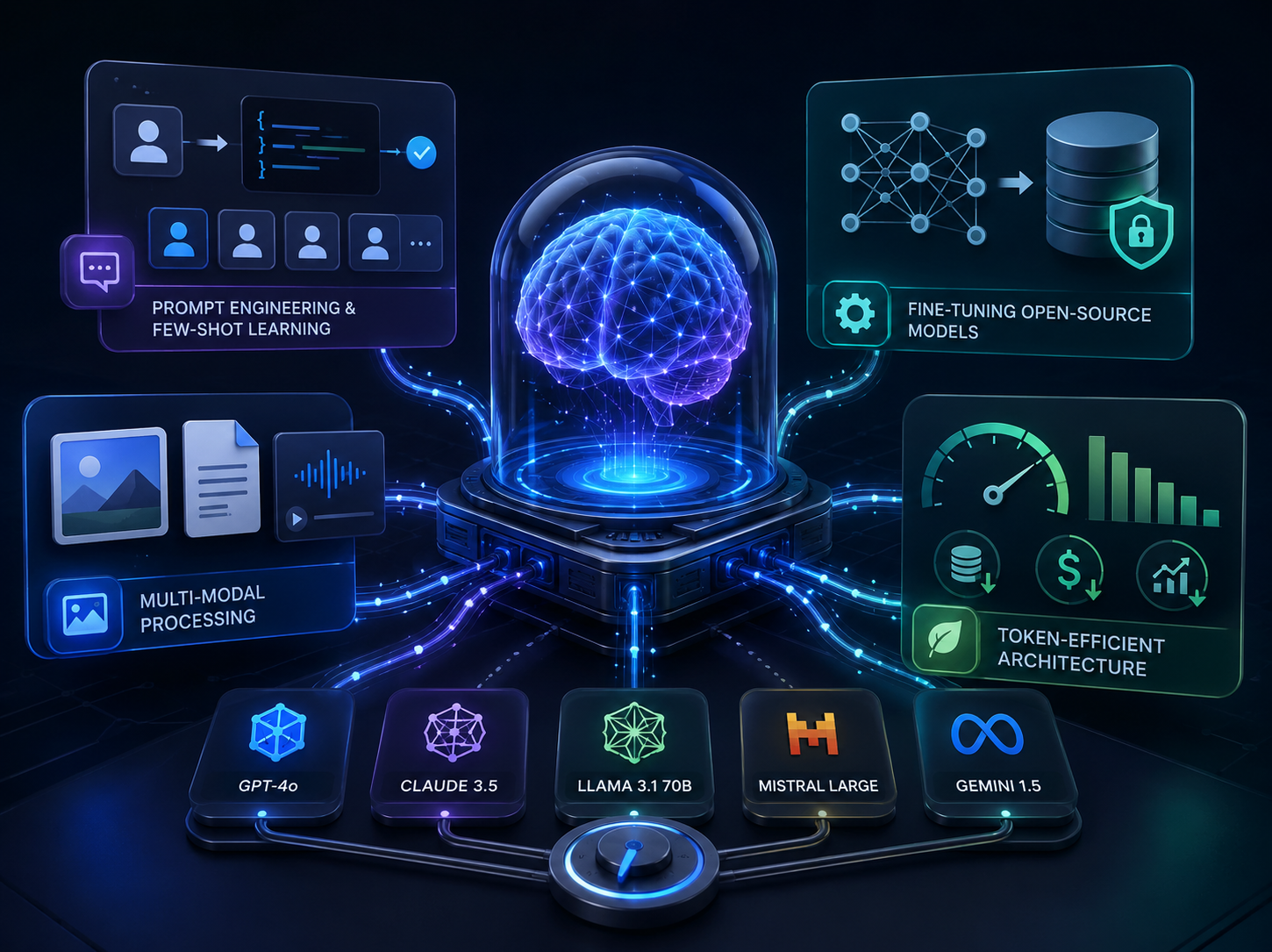
Selecting the correct Large Language Model (LLM) is the most critical architectural decision in the development of any AI application. Treating all LLMs as interchangeable commodities is a recipe for bloated costs and sub-optimal performance. We act as model-agnostic architects, rigorously evaluating and deploying the precise model that perfectly aligns with the specific cognitive requirements, latency constraints, and economic realities of your use case. We do not restrict ourselves to a single ecosystem; we utilize the absolute best tool for the job.
For highly complex logical reasoning, advanced coding tasks, and robust tool-use (function calling), we frequently integrate OpenAI's GPT-4o. When the task requires analyzing massive, multi-hundred-page legal documents or maintaining context over incredibly long conversations, we deploy Anthropic's Claude 3.5, which boasts unparalleled context windows and highly nuanced, less-refusally logic. For enterprises operating in heavily regulated sectors (like healthcare or finance) requiring absolute data sovereignty and zero external API calls, we specialize in fine-tuning and hosting powerful open-weight models, such as Meta's Llama 3, entirely on secure, private, on-premise GPU infrastructure.
Beyond model selection, we implement rigorous engineering standards to manage the operational costs of AI. Because proprietary LLMs charge based on "tokens" (fragments of words), an unoptimized application can quickly become economically unviable at scale. We aggressively optimize system prompts to be token-efficient, implement advanced semantic caching layers (so identical queries are served from a database rather than re-computing the LLM call), and utilize cheaper, faster models (like Claude Haiku or GPT-4o-mini) for simple classification tasks, reserving the heavy, expensive models exclusively for deep reasoning.